Introduction to The Theory of Computation
7/21/2024|Academic|6 min read
Introduction
The Theory of Computation is about how machines can process formal languages; i.e. how we can describe patterns of strings such as aaa, aabaa so that a machine can read/recognize them.
There are three major problems that you should keep asking about:
- What problems are computers capable of solving?
- What resources are needed to solve a problem?
- Are some problems hard than others?
A Problem
Before talking about the detail of computer theory, it is important to define what is a problem.
The Theory of Computation focuses on decision problems the most; i.e. making a decision or computing a value based on some input.
Additionally, the difficulty of a problem is positively correlated to the number of resources the problem requires to be solved.
Vocabulary
- Character/Symbol:
a,b,c,0,1, ... - Alphabet: a non-empty set of symbols
- Word/String: a sequence of symbols:
000111000,AceY,Aron, ... - Language: a set of strings
Language Operations
Let and be languages over the alphabet .
Union
is the language that includes any string that is either in or .
Concatenation
is the language that includes any string from concatenated with any string from .
Kleene Star
is the set of all finite strings made up of concatenations of elements of .
Language
Regular Language
A regular language is a language that can be described with a Regular Expression (RegEx) or recognized by a Deterministic Finite Automaton (DFA) or a Nondeterministic Finite Automaton (DFA).
A regular language is closed under:
- Union
- Concatenation
- Kleene Star
- Complementation
Regular Expression (RegEx)
A regular expression is a string of symbols that describes a language.
is a regular expression over the alphabet if:
- , where
- , where , are themselves regular expressions
- , where , are themselves regular expressions
- , where is a regular expression
Notation: As mentioned above, a regular expression is a string of symbols that follow particular rules. Moreover, the alphabet of allowable symbols you can use for a regular expression is:
Say we have a language that can be described as , then:
Deterministic Finite Automaton (DFA)
A deterministic finite automaton is a directed graph with the following properties:
- The vertices of the graph are called states
- The edges of the graph are called transitions
- The transitions are labeled with characters from an alphabet
- Each vertex has one outgoing edge for each character in
- Exactly one vertex is labeled as the "start state"
- Each vertex is either an accept state or not
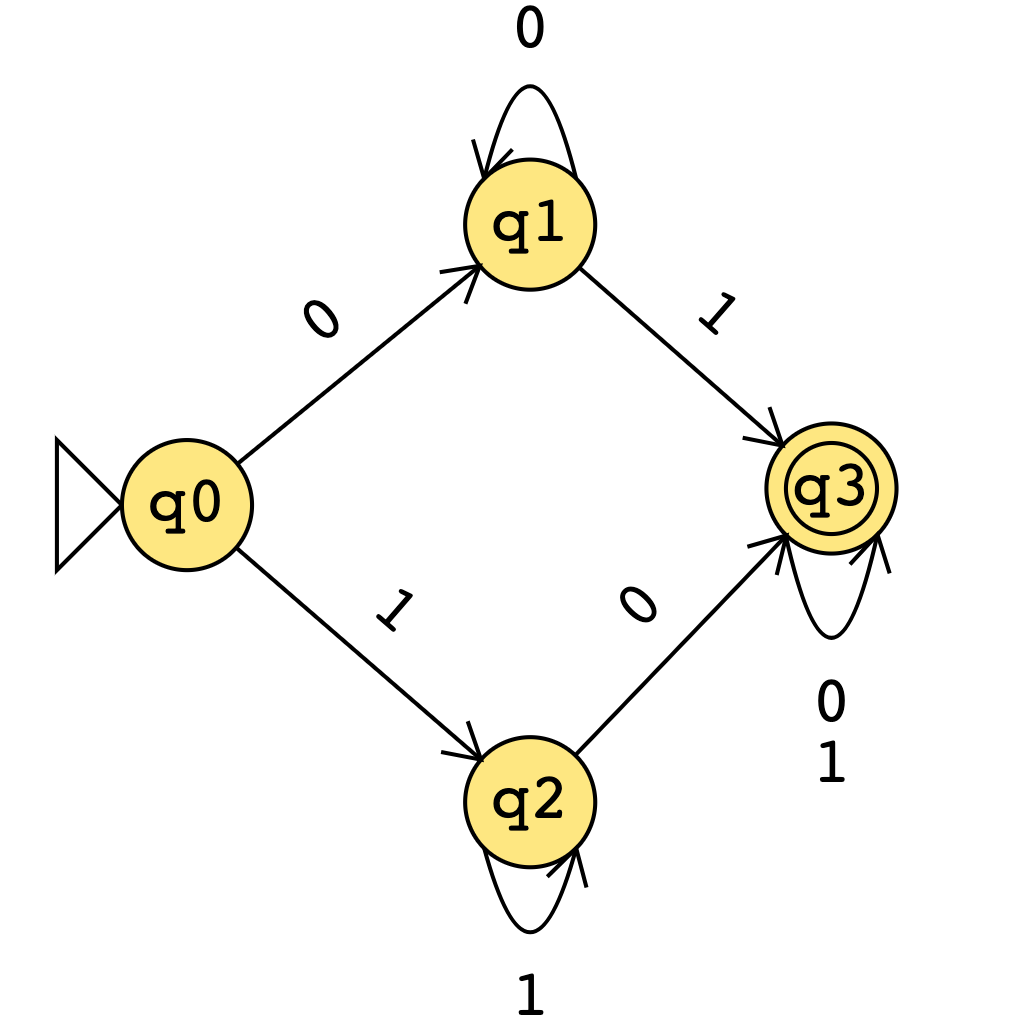
Notation: Formally, we can define a DFA with a 5-tuple where:
- is a finite set called the states
- is a finite set called the alphabet
- is the transition function
- is the start state
- is the set of accept states
Therefore, with the notation, we can describe the above DFA by where the function is specified by:
| State | Input | Output |
|---|---|---|
Nondeterministic Finite Automaton (NFA)
A nondeterministic finite automaton has the same properties as a DFA except for vertexes. Instead, an NFA's vertexes can:
- Have any number of edges
- Have epsilon (the empty string ) transitions
Notation: Formally, we can define an NFA with a 5-tuple where:
- is a finite set called the states
- is a finite set called the alphabet
- is the transition function
- is the start state
- is the set of accept states
DFA vs NFA vs RegEx
Every DFA is essentially an NFA since it meets all the properties that an NFA possesses. On the other hand, an NFA can always be converted to a DFA with the standard subset construction.
Similarly, regex can be converted to NFAs using structural induction, and a DFA can be converted to a regex using generalized nondeterministic finite automata (GNFAs).
Non-regular Language
A DFA can have some "memory" —— states. A DFA is finite because it can only "remember":
- finitely far in the past
- finitely much information
In other words, if a computation path visits the same state more than once, the machine cannot tell the difference between the first time and the future times it visited the state.
is an example of a non-regular language; there is no way one can design a DFA that recognizes this language. The inability is caused by the variable that is used twice to control the number of zeros in the front matches the number of zeros at the back.
Proof of A Non-regular Language: The Pumping Lemma
Human brains are finite as well; there is no way for one to test all the possible DFAs to prove the non-regularity of a language. However, there is a lemma that can help us.
The pumping lemma says: if is a regular language, then a number (the pumping length) where, if is any string in language of length at least , then may be divided into three pieces, such that:
- , AND
- , , AND,
With these properties, we can easily prove if a language is non-regular.
Limitation: Note that in practice, there are non-regular languages that follow the pumping lemma. Therefore, the pumping lemma can only be used to prove the non-regularity and it is never sufficient to prove if any language is regular.
Example 1: Prove is not regular.
Claim: The language is not regular.
Proof: Consider an arbitrary positive integer . WTS is not a pumping length for .
Assume the language is regular.
Consider the string , , since the language is regular, then can be pumped.
Apply the pumping lemma, the string can be divided into three parts:
Then by pumping lemma, we know that , while .
Thus, is a string that has more zeros than ones, so . Contradiction!
Therefore, the language is non-regular.
Trick: it makes the proof clean and simple to make the first part of the string be length since there is only one way to split the string.
Example 2: Prove is not regular.
Claim: the language is not regular.
Proof: Assume the language is regular.
Consider the string where .
Apply the pumping lemma, then .
Let , can be divided into three parts:
Then by pumping lemma, we know that , while .
Thus, is a string that has more zeros in the first half than the latter half, so . Contradiction!
Therefore, the language is non-regular.
Trick: when trying to prove a very broad-defined language, we can pick the string pattern in our favor. As long as the picked string follows the defined pattern when proving its non-regularity, pumping can always push it to the original "space" where the language the not defined.
Context-free Language
A context-free language is a language that can be recognized by a Context-free Grammar (CFG) or a Pushdown Automaton (PDA).
A context-free language is closed under:
- Union
- Concatenation
- Kleene Star